The entire point of having a website is to be able to connect with your target audience and get traffic that produces revenue. All the backlinks and awesome content you put on it are nothing if search engines cant crawl and index your pages.

The entire point of having a website is to be able to connect with your target audience and get traffic that produces revenue. All the backlinks and awesome content you put on it are nothing if search engines cant crawl and index your pages.

This article is going to help you understand what indexability and crawlability are, how they are affected by different factors, how you can make your website easier to crawl and index for search engines, and well close with a few useful tools to manage your digital propertys crawlability and indexability.
Before we jump into the water, lets get our feet wet by taking a quick look at what Matt Cutts, a former Google employee, has to say about how search engines discover and index pages.
According to Google,
Crawlers look at web pages and follow links on those pages, much like you would if you were browsing content on the web. They go from link to link and bring data about those webpages back to Googles servers.
In other words, if you care about SEO and why its important, its a good idea to make your website as indexable and crawlable as possible.
Indexability is the ability of search engines to add your web page to their index. There is a chance that Google is able to crawl your site, but may not be able to index it due to outstanding indexability issues.
Heres a screenshot of a page that is indexable, and a link to the tool in the Chrome Store

Search engines need to access your site and crawl the content on your pages in order to understand what your site is about.
Spiders crawl your site by moving through links between pages. Thats why a good linking structure and a sitemap are useful, along with a solid website crawl checker
Things like broken links and dead ends might hinder the search engines ability to crawl your site.
This is a screenshot of a URL that has passed a crawlability test.
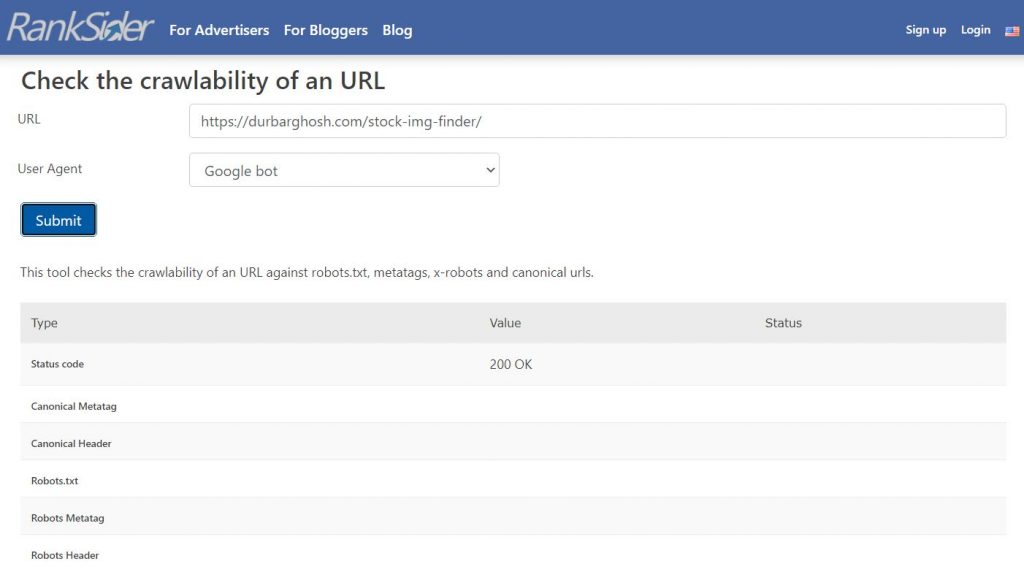
Whether youre an experienced SEO or just a beginner looking for an SEO guide, keeping an eye on the following factors is crucial.
Having a weak site structure will hinder the robots ability to crawl and index your site. Structure issues include pages that have no incoming links pointing to them, for example.
Having a good internal linking structure will help the crawlers navigate through your website with ease, not missing any content and indexing your website correctly.
Google Search Console is a great tool to check your link structure, as you can see here:

Broken page redirects will completely stop a crawler and cause immediate issues.
Server-related issues will impede crawlers to do their job right.
This is what a server error might look like. Does it look familiar?

There are different technologies and scripts that can cause issues. For example, crawlers cant follow forms, so content gated behind form will have issues being crawled. Javascript and Ajax may cause similar negative results.
There are a few reasons for you to block crawlers from indexing your pages on purpose, including having pages with restricted public access.
However, make sure youre careful not to block other pages by mistake.
These are the most common factors affecting crawlability and indexability, however, there are many more factors that can make your website crawler-Unfriendly.

You know the importance of link building and other SEO tactics. But regularly checking the aspects below is a good practice to help you keep your site healthy.
Paying attention to detail is important. Even as an experienced SEOs, you might accidentally insert or forget to remove a noindex, follow tag.
This might look like this:
When you configure your robots.txt file, you can give search engine crawlers specific instructions as to which directories should be crawled.
Make sure you dont accidentally exclude important directories or block any of your pages. Theres a good chance that the Googlebot will end up finding your pages through backlinks but if you correctly configure your robot.txt file, it will be easier for search engines to crawl your site regularly.
The most common uses for .htaccess files are:
These files can potentially prevent your page from showing up on search results and perceive crawlers as unauthorized access. The .htaccess is a control file stored in a directory of the Apache server.
In order for your .htaccess rules to be executed, you must always name the file exactly the same way. For example:
Redirecting or rewriting URLs:
RewriteEngine On
Rewriting requires using:
RewriteBase /
Define the rule that the server is to execute:
RewriteEngine On
RewriteBase /
RewriteRule seitea.html seiteb.html [R=301]
If the file was named incorrectly, it will not be able to rewrite or redirect URLs, causing users and crawlers to not be able to access, crawl, or index the pages.
Canonical tags help you prevent duplicate content issues by specifying the preferred version of a page for crawlers.
These are the most common errors you can make when setting your Canonical tags:

If your server fails, crawlers wont be able to index your pages. Just like users wont be able to access it, its impossible for crawlers to do it as well.
To stay on top of any issue, you should regularly check your site for 404 pages and 301 redirects to be working properly.
Heres a screenshot of a server error message.

Make sure new pages, new categories, and any new restructuring you might add to your site are linked internally and listed in the sitemap.xml. The most important tip regarding orphaned pages is to avoid them no matter what.
Content theft, to put it bluntly. External pages may have duplicated your content and this might make them rank better than you, or, even worse, prevent your content from being indexed at all.
Google is pretty good at knowing which one is the original content, but you can find this stolen content by performing a search of some of the most key and original phrases in your piece.
If any of your internal pages are labeled with the rel=nofollow attribute, they will not be crawled or indexed by Googlebot. Make sure you check and adjust accordingly.
If your XML sitemap does not contain all the URLs to be indexed, youll have to deal with a problem similar to orphaned pages.
The screenshot below shows Sitemaps submitted in Google Search Console.

To make sure your pages dont get hacked take the following actions:

Besides making sure the issues listed above dont happen to you, you can also take proactive steps into making sure your site is properly configured to be crawled and indexed correctly.
Your sitemap will help Google and other search engines better crawl and index your site.
This is what submitting a sitemap looks like in Google Search Console.

A strong interlinking profile will certainly make it easier for search engines to crawl and index your site. It will also help with your general SEO and user experience.
Updating and adding new content to your site is a great recipe for improving your rankings and SEO health, as well as user experience. Another advantage of doing this is that it will make crawlers revisit your site more often to be indexed.
Once you do, you can ask Google to reindex your page. It looks like this:

Having duplicate content on your site will decrease the frequency with which crawlers visit your site. Its also a bad practice regarding your SEO health.
Crawlers have a crawl budget. And they cant spend it all on a slow website. If your site loads fast, theyll have time to crawl it properly. If it takes too long to load and the crawlers time (crawl budget) runs out, theyll be out of there and on to the next website before crawling all your pages. Page load time is a big factor, even by ordering quality backlinks, unless your site is operating at a good enough speed, you'll dilute the value provided by your SEO effoerts.

The screenshot above is part of the results PageSpeed Insights from Google gives you.
The web is filled with tools that will help you monitor your website and detect any indexability and crawlability issues on time. Most of them have free tools or free trials that will allow you to check your site.
Google also offers you the ability to manage your sites crawlability and indexability through tools like Google Search Console and Google PageSpeed Insights.
Once you land on Google PageSpeed Insights, you get a screen like this:

Making sure your website is properly configured to be indexed and crawled by search engines is a smart business decision. Most of the times websites are business tools to attract and convert. This is why taking all required steps to be indexed and crawled by search engines correctly needs to be part of your overall SEO strategy and maintenance.
Checklist:
Link to checklist
